 David Yates.
David Yates.FaceApp, a phone application that people use to transform photographs of themselves in amusing ways, was recently in the news over various privacy concerns. The story boiled down to this: in order to use an application that edits your photos, you have to give that application access to your photos. And this particular app was developed by Russians. So by downloading this app you were helping the Russians to get Donald Trump re-elected, probably.
This story fed into a lot of pathologies and misunderstandings about privacy, social media, and the Russian fake news meme, subjects I’ve been thinking about a lot lately. I think a lot of reporting and mainstream thinking on these issues is based on a lack of understanding and thought about how all of these things work and relate to each other, and that lack of understanding leads people to bizarre conclusions. So I’d like to take this rather lengthy post to lay out my understanding of these issues, based on much thought and my technical background. Spirited disagreement most welcome.
# I – Fake news
Let’s start with a personal story. During Crushly’s brief existence, some accomplices and I had another, rather more ignoble project on the go: a little blog that would today be called a “fake news website”. But this was 2014, before that meme was even a twitch in Trump’s Twitter finger.
The idea’s genesis was social media comments I’d seen on postings from a regular and successful satirical blog run by a journalism student at my university (and some less successful copycats). The blog was framed as a news site and the posts as humorous, obviously fake news articles intended to make some broader point, ala The Onion. However, certain posts would provoke genuine outrage, which tended to be more dependent on their headlines than their content. In all cases, this outrage would hinge on a shallow reading of the headline and/or article that took it either as fact or non-satirical opinion.
From this, I formulated the hypothesis that people believe things they read on Facebook without investigating their source, or, in many cases, even reading the actual article beyond its headline. Our fake news website was intended to test this hypothesis. We bought a domain, I spun up a fairly rudimentary-looking instance of Ghost, one of my accomplices edited the CNN logo a bit, and we started publishing fake news. Stories included: “Eastern Cape Learners Paid to Teach” and “Possible Ebola Outbreak in Grahamstown”.
The experiment failed. No-one believed the obviously fake, low-effort stories on our lousy website. Comments on our Facebook shares included “This is the worst satirical news site so far” and “I smell lies”. This surprised me at the time, as lower effort stories on much worse-looking websites had sparked belief and outrage. How was satirenews.blogspot.com beating legitsoundingnewsnetwork.co.za (not their real URLS)?
In hindsight, the answer is obvious: no-one wanted to believe our fake news (or to strongly disbelieve it). Our articles were ridiculous, often entirely nonsensical – there was one entitled “Disgruntled Students to Strike” that was made up entirely of puns about striking out and striking matches – and, most importantly, not controversial. Our articles did not reinforce or attack anyone’s identity. There’s no point in writing fake news that doesn’t reinforce your audience’s biases.
# II – The social graph
The most menacing thing in the world is the ability of the cloud to correlate its contents.
Zero HP Lovecraft, The Gig Economy
In recent years, the spread of fake news on social media has become a topic of much wider sensation than it was during our website’s short and forgettable career. The nucleus around which this topic revolves is Donald Trump’s surprise 2016 US election win, with fake news talking points on the left being alleged Russian manipulation of social media, and fake news talking points on the right being alleged left-wing bias in the mainstream media. Last year, Facebook came under fire for message-targeting services provided by political consulting firm Cambridge Analytica to various political causes, with people around the world enraged about the way Facebook allowed its users’ personal data to be used.
Jonathan Albright details Facebook’s Graph API in this Medium post, making the point that Cambridge Analytica gathered the data it did merely by using the API as intended. Despite the misleading title of the recently released Netflix documentary about the saga, no hacking was involved. Online advertising’s killer feature has always been targeting, and Facebook is arguably the world’s largest and most comprehensive catalogue of targets. And what is a political candidate but a product to be advertised?
If you’re a Facebook user with some metadata about your age, sex and location, that’s useful for targeting. But if you have a few hundred friends, and a bunch of liked pages, that’s way better, because we can draw lines between you, your friends, your pages, your friends’ pages, your friends’ friends, and so on. And all those friends and pages will have their own metadata, so you and them and everything can be linked together in a great big web that can generate implied metadata – for example, if you don’t specify where you live, Facebook could make the reasonable assumption that you live nearby the largest group of your friends who do specify their location.1 At a great enough scale, no data is anonymised.
Graph databases allow the cloud to correlate its contents. In 2010, this was heralded as a (positive) game-changer – Facebook’s Google-Killer App – a reinvention of the semantic web with Facebook at the centre. And one can see how such a graph would be highly appealing to programmers at Facebook, with their enormous wealth of data to play with. They clearly wanted nothing more than to open these possibilities up to the developer public, and allow Facebook Apps to use it in ways that would entrench Facebook’s dominance of the social media world.
On one hand, having your web experience customized to your tastes, interests and relationships is appealing. On the other, it’s going to be hard to keep track of all of the personal data you’ll be publishing to the graph for all to see — and there might be some opportunities for abuse by less scrupulous companies.
Samuel Axon, Facebook’s Open Graph Personalizes the Web
A web of relationships is worth much more than the sum of its parts. In the cybersecurity field, we use a tool called BloodHound to map relationships in Windows domain environments. This innovative application of the graph database made the time-consuming and largely blind endeavour of lateral movement through Windows domains (e.g. moving from a piece of malware on a low-ranking employee’s PC to the bank’s SWIFT infrastructure) essentially a solved problem. What’s more, a single dataset allows you to instantly map out every single path through the network, so when you’re done with the SWIFT server, you can move to payroll or maybe a super sensitive database. Or, if one path is closed up, you can switch to a different one.
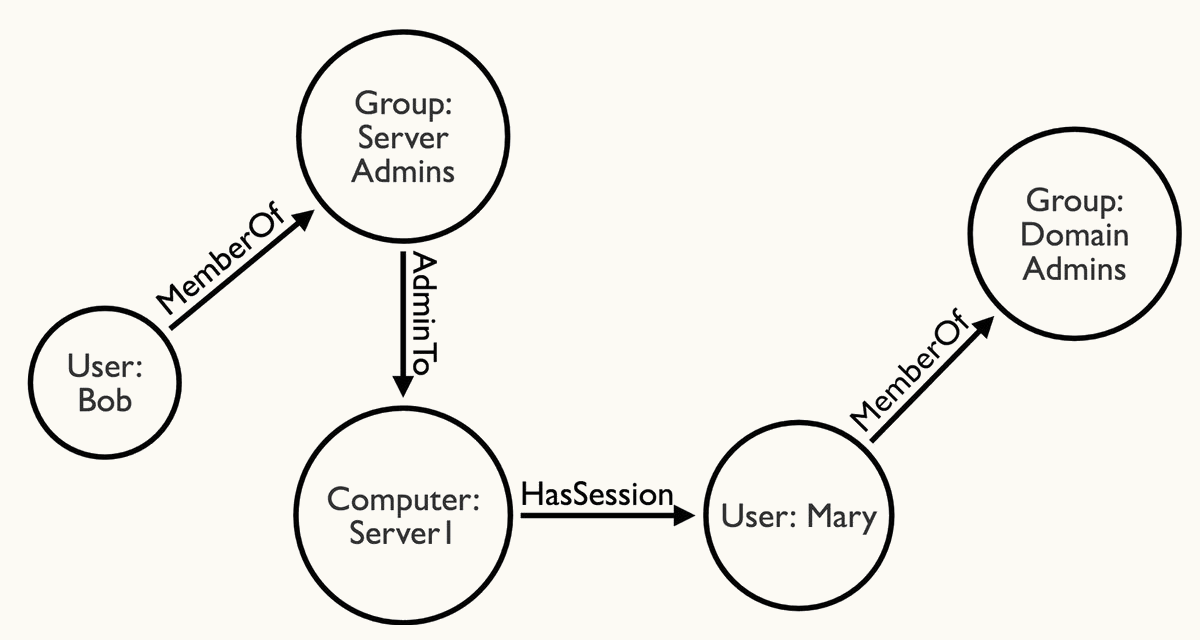
BloodHound AD relationship graphing (source).
But none of this becomes obvious until you actually build the database and map out the relationships. In both cybersecurity and social media. To the average Joe Facebook, or probably even the average Joe Facebook Developer, the sheer scope and possibility that the social graph opened up were inconceivable. It took experimentation to discover what could be done, and it took years for the masses to realise what had been done.
Facebook and similar businesses make money by leveraging their trove of willingly provided personal information and captive audience to sell ads. John Wanamaker, an early 20th century US department store magnate, famously said, “Half the money I spend on advertising is wasted; the trouble is I don’t know which half.” Facebook’s value proposition is eliminating that wasted half through highly sophisticated targeting.
The most obvious application of this is something like, “I run a niche business that sells premium gaming chairs, and would like to advertise only to males between 21 and 35 in high-paying careers who have expressed interest in PC gaming.” But this is just the tip of the iceberg. “I would like to send $MESSAGE to $PEOPLE where $PEOPLE is described by $ATTRIBUTES” is really what it enables. Fine-tune your $ATTRIBUTES enough, and you can even target an audience of one to play a prank or ask for a job.
The other, much more nefarious thing you can do, is use ad targeting to send people fake news and/or political adverts that do reinforce or attack their identity. And because Facebook’s advertising placement system is entirely automated, you can do this without anyone asking questions – at least at first.
When you make something frictionless — which is another way of describing zero transaction costs — it becomes easier to do everything, both good and evil.
Ben Thompson, The Super-Aggregators and the Russians
That’s just how the system works.
- You sign up on social networking websites and enter your personal information.
- The networks’ developers put together a self-service ad platform that leverages their core value proposition.
- All your friends sign up and add their info.
- Advertisers get in on the game.
All of the above are nodes in a graph, connected by vertices that together map out a territory of unintended consequences.
To avoid these consequences, there have been some pushes to deliberately, artificially block off parts of the graph, many of which give large incumbent players like Facebook more power and small outfits like Cambridge Analytica less. As an open API, the social graph is crippled, but Facebook itself can still use the original.
The good news? They’re not selling your data to anyone… for the same reason Coca-Cola hasn’t sold its recipe. Your data is their competitive advantage.
# III – Privacy from the machines
Years ago, I read a book called The Google Story, about the founding and early successes of Google, from the founding of the search engine to the development of other products such as Gmail. The book was released in 2005, and I read it around 2007 or 2008, shortly after making my first Gmail account. From what I remember, the book really hammered on the point of Larry and Sergey being super smart guys who pretty much never made any mistakes in Google’s early years. They kept the homepage clean and simple, avoided Yahooising into a portal, ingeniously used a distributed system built from consumer hardware to power the search backend, and built a special share scheme that ensured their continuing control after Google’s IPO. The only time they seem to have slightly gone off track was with the introduction of Gmail and the controversy around its advertising.
Gmail was (and is) a free email service with a slick UI that gave users a large amount of storage space for their mail. To monetise it, Google showed personalised ads around the inbox. These ads were personalised using the content of the user’s mails. Cue the privacy freak out.
Reading about it at the time, I thought the whole issue sounded massively overblown. Google’s value proposition was targeted, personalised advertising – the dream of driving down the highway and seeing only billboards relevant to your interests and purchasing habits. Furthermore, the ad personalisation was done by algorithms – it’s not like another human would be reading your emails and recommending you stuff. Only machines would see your mails.
Of course, the idea that only machines would see your mails was something you had to trust Google on. By extension, though, that was a level of trust you’d be placing in any free or paid email provider operating infrastructure outside of your control, regardless of whether advertising was happening or not. By using social media, or hosted email, or apps that change photos of your face through machine learning, you’re trading some level of personal privacy (or at least certainty about personal privacy) for whatever that service gives you. This isn’t a black-and-white picture – certain providers market themselves on privacy and most social networks have various privacy sliders – but you have to trust your provider.
Take Grammarly. For the sake of improved spelling, grammar and style, you’re installing a browser extension that sends most of what you type to a remote server. People seem to get really freaked out about that every once in a while and engage in mass uninstalling, but how did they think it worked? It’s a cloud service for checking your writing: of course it sends everything you type to their servers.2 Where it is read by machines. You trust.
Free services are subsidised by advertising. In the Internet age, advertising means targeted advertising, and targeted advertising means your data is being collected and collated by machines to sell you things you’re more likely to buy. This is something I always took to be an obvious given. Watching the Zuckerberg hearings last year, I was shocked by how many of the questioners didn’t seem to grasp that this was how Facebook made their money. Social media isn’t a charity – Zuckerberg doesn’t give you a place to post pictures and opinions out of the goodness of his heart.
Being a social media user and at the same time clamouring for privacy strikes me as inherently contradictory. Even with the strictest privacy settings and the fewest & least filled out accounts, the point of social media is to violate your own privacy by sharing things with others, permanently. Snapchat and the features Zuck’s platforms copied from it (stories) are an attempt at ephemeralising social media, but making content truly ephemeral on computers is about as possible as effectively copy-protecting it (you can’t). If you want the dopamine hits from those likes and comments, you’re going to have to sacrifice some privacy, at least from the machines, by becoming a node on the graph. That’s the deal.
# IV – What to do
A lot of otherwise rational and sensible people adopt horrifyingly censorious attitudes when discussing how to address the problem of fake news. I’ve heard proposals to black out social media around elections – exactly the tactics of oppressive regimes in countries like Zimbabwe. Slightly softer than that are the demands that social media platforms police fake news, which can only lead to a dangerous level of centralisation – given the sheer scale of the dominant social platforms, the power of their censor is greater than that of many countries. And while the push is to use this censorship for good, there’s just no way that a single corporate entity like Facebook can be trusted to make the necessary judgement calls about what is good, what is factual and what should be allowed to spread in every part of the world where they operate.
The only solution to fake news that doesn’t involve a push for totalitarianism is to educate the audience and expect better and more critical thinking from the average person. Recognise that you are a target for politicians seeking your vote, recognise that you are predisposed to believe news stories that confirm your existing beliefs, and do a bit of fact-checking. Fake news may be an Internet-age phenomenon, but the Internet age has also given us the tools to overcome it. To throw your hands up and wait for Facebook to do something about it is to abdicate personal responsibility and ask to be protected by a company whose real customers are advertisers.
And if you really, really want to keep something private, don’t upload it to the cloud (someone else’s server). At least not unencrypted. If you truly value your privacy, think about the graph. Understand that the cloud can correlate its contents.
Not saying they did or didn’t – I honestly don’t know if this sort of thing was done. ↩︎
One could argue that Grammarly should do all their checks locally with the JavaScript in their browser extension. The trouble with this – and the reason all software operates on a service model nowadays – is piracy. If Grammarly Pro did everything client-side, it would instantly get cloned by a million opportunistic upstarts. The code that checks your writing is their secret sauce, so they need to keep it on their servers. ↩︎