 David Yates.
David Yates.I ended my last post about AI image generation on the following note:
↗DALL-E 3’s ability to create pleasant, mostly coherent images with plenty of fine detail from text prompts alone makes many of the Stable Diffusion techniques above feel like kludgey workarounds compensating for an inferior text-to-image core.
[…]
I think it’s also likely that OpenAI is leveraging the same secret sauce present in ChatGPT to understand prompts. As far as they’re concerned, generating pictures is a side-effect of the true goal: creating a machine that understands us.
Me in October 2023, Adventures in latent space
Eighteen months later, OpenAI has done it again: released a new text-to-image model that blows the competition out of the water and shows that the alpha in improved prompt adherence is far from exhausted.
The image generator has entered the public consciousness largely through a trend of converting memes, selfies, and historical photographs into pictures in the style of Studio Ghibli films, muppets, and South Park characters.1
“Break a leg!”
This general idea has been a perennially popular way of using AI, but the results have never looked this good. Many different approaches are available:
- You can prompt for “X in the style of Y”.
- You can prompt for “X in the style of Y” and use the picture you want to change as an input image.
- You can prompt for “X in the style of Y”, using a specially fine-tuned model or LoRA.
- You can prompt for “X in the style of Y”, use IPAdapter with a style reference and a content reference.
- You can prompt for “X in the style of Y”, using a reference or style ControlNet.
Methods 1 and 2 have historically been very hit-and-miss. Methods 3 to 5 can be combined, but require a lot of fiddling with settings and patience with RNG. With GPT4o’s image generation, method 2 beats everything I’ve seen from any other model, local or otherwise. But style transfer is far from GPT4o image generation’s sole use.
You can make precise edits to images, and produce paragraphs of 99% correct text.

Original

Watchmen-style textboxes added

More text generation
Prompt adherence is good enough to correctly compose an image from Scott Alexander’s 2022 stained glass challenge.
Generate a stained glass picture of a woman in a library with a raven on her shoulder with a key in its mouth

First attempt

Second attempt
It also rises to the more recent challenges of creating an analogue clock with correct numbers and a full wine glass:

It doesn’t appear to solve the 10:10 problem though.

Full to the brim.
It’s possible to get images with transparent backgrounds:
![]()
Or recreate one image in the style of another:

Content – The Lost Room, 2006


Result – Lost Room: The Game
Or combine the contents of three or more images in complex ways:

Images that have been through a few rounds of manipulation seem to develop a yellow filter.
This result was not terribly satisfactory as the wine glass also didn’t stay full and the clock’s numbering suffered a little. I also hit a rate limit when generating it, which may be partially responsible for the horizontal truncation. Still, I’m amazed that this was possible just by uploading the three images and asking for the clock to go on the wall and the wine glass to go on the table. Good luck doing that in any other diffusion model without opening an image editor!
Most impressively, GPT4o can generate multiple images with consistent characters in a consistent style. It can actually create coherent comics in response to detailed prompts specifying what each panel should contain!


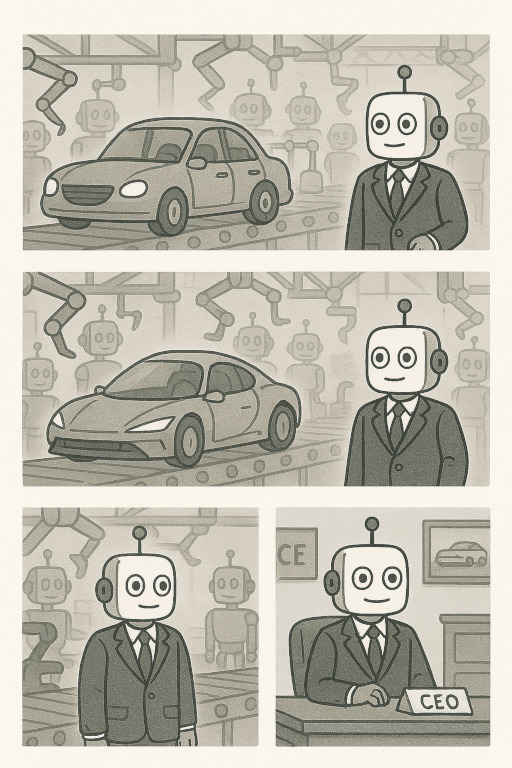


This last one is really fun – you can tell ChatGPT a story and it will illustrate it in real time.
In my previous post, I briefly mentioned how ChatGPT would expand and vary user-supplied image generation prompts before feeding them to DALL-E 3. This allowed for levels of context not possible in standalone generation workflows – the language model could and would use information from your chat history to generate its prompts. So you could say things like, “Generate an image of a man named Bob with a curled moustache and a bowler hat”, followed by, “Now show Bob with his pal Charlie, who has a beard and a chef’s hat”, rather than having to write the prompt from scratch each time. Or you could say, “Generate another one of those but leave out the bowler hat.”
GPT4o’s image generation compounds this advantage. Rather than being an external model tool that GPT knows how to interact with, it’s a fundamental part of the model itself. Image generation benefits from the concepts understood by the text generation part of the model.
But that’s not all! The title of this post references the fundamental difference between this image generation technique and the open and proprietary image models that have dominated the scene since DALL-E 2 – pixel space vs latent space. While DALL-E 2, Midjourney, Stable Diffusion, and most other image models use diffusion to generate images, this new model is autoregressive. This is actually an older approach to image generation, harking back to DALL-E 1, and a standard approach to text generation.
Diffusion models create images by starting with a canvas of random noise and repeatedly denoising it based on a text prompt. This means that the whole image is drawn at once, starting with blurry shapes that define the composition and progressing toward fine detail. This image from my first Stable Diffusion post gives an idea:

In contrast, autoregressive models generate images in batches of pixels, generally moving from the top-left to the bottom-right. Each patch is predicted with the context of the previous patches, just like how text generation works. You can see this at work in how gpt4o slowly draws images from top to bottom (occasionally getting stuck partway due to rate limits or emergent content violations).

What’s also interesting about this image is that the unrendered part looks a little like a very early-stage diffusion generation. There’s some speculation that 4o uses a combination of an autoregressive model and diffusion. This may explain why edited images always contain minor differences beyond the intended edit(s), as shown in a couple of outputs above.

OpenAI’s stuff is all proprietary and top secret for reasons of Safety™, so we don’t know exactly what they’re doing here, or exactly how they’ve made the autoregressive approach totally leapfrog diffusion for image generation.2 We can speculate that this more sequential approach leads to 4o’s greater image coherence and relative lack of weird artefacts, extra limbs, and other problems that plague diffusion models. Or perhaps the output quality is more down to gains in prompt understanding brought about by the model’s multimodal nature. Notably, though, Gemini 2.5 and Grok 3 are also multimodal models with autoregressive image generation but do not achieve nearly the same output quality. Perhaps this comes down to model size or training data quality.
Jealous, Gemini?
Whatever the case, the results speak for themselves. Workflows that previously required an SSD full of LoRAs, monstrous ComfyUI workflows, meticulous inpainting, and endless re-de-noising can now be accomplished in a chat. There is probably still some utility to these and other diffusion workflows – some parts of the robot comic above could benefit from inpainting, for example. And until 4o-level models become more widely accessible, diffusion remains the state of the art for local generation. Perhaps until Deepseek releases a new iteration of the Janus series.
You can also make Studio Ghibli scenes in the style of real photographs. ↩︎
Amusingly, this is happening at the same time as researchers are looking into generating text with diffusion rather than autoregression, citing significant increases in generation speed. ↩︎